728x90
데이터 전처리
>데이터를 그대로 사용하지 않고, 가공해서 모델을 학습시키는데 좀 더 좋은 형식으로 만들어 주는 것
Feature Scaling (입력 변수/속성 조정하다)
> 입력 변수들의 크기를 조절 일정 범위 내에 떨어지도록 바꾸는 것
ex) 연봉과 나이의 데이터 크기는 차이가 많이 나기 때문에 일정 범위로 통일하는 것
> 경사 하강법을 좀 더 빨리할 수 있게 도와준다!
- min-max normalization (최솟값, 최댓값을 이용해서 숫자의 크기를 0과 1사이로 만든다.)
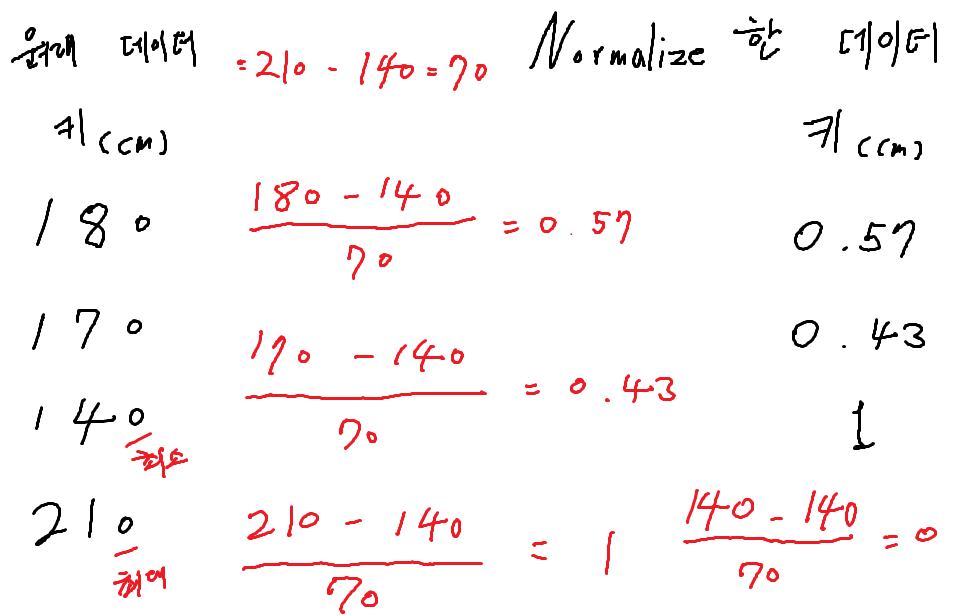
1. 최댓값에서 최솟값을 뺀다. 210 - 140 = 70
2. 원래 데이터에서 최솟값을 뺀다. 180 - 140
3. 그리고 최댓값과 최솟값의 차이만큼의 값으로 나누어 준다.
4. 그럼 0과 1사이의 값이 나오게 된다.
실습
import pandas as pd
import numpy as np
from sklearn import preprocessing
MBA_FILE_PATH = 'C:/Users/user/Desktop/NBA_player_of_the_week.csv'
nba_player_of_the_week_df = pd.read_csv(MBA_FILE_PATH)
nba_player_of_the_week_df.head()
nba_player_of_the_week_df.describe() #간단한 통계도 확인가능
Weight Age Draft Year Seasons in league Season short Real_value Height CM Weight KG Last Season
count 1340.000000 1340.000000 1340.000000 1340.000000 1340.000000 1340.000000 1340.000000 1340.000000 1340.000000
mean 224.567164 26.738060 1996.287313 5.740299 2003.156716 0.686940 201.071642 101.384328 0.023881
std 30.798885 3.400683 11.253558 3.293421 11.470164 0.242007 9.367970 14.011226 0.152734
min 150.000000 19.000000 1965.000000 0.000000 1980.000000 0.500000 175.000000 68.000000 0.000000
25% 205.000000 24.000000 1987.000000 3.000000 1994.000000 0.500000 193.000000 93.000000 0.000000
50% 220.000000 26.000000 1998.000000 5.000000 2005.000000 0.500000 201.000000 99.000000 0.000000
75% 250.000000 29.000000 2005.000000 8.000000 2013.000000 1.000000 208.000000 113.000000 0.000000
max 325.000000 40.000000 2018.000000 17.000000 2020.000000 1.000000 229.000000 147.000000 1.000000파일을 가져오고 Height, Weight, age 값을 Feature Scaling 해보려고 한다.
height_weight_age_df = nba_player_of_the_week_df[['Height CM', 'Weight KG', 'Age']]
height_weight_age_df.head()
Height CM Weight KG Age
0 203 94 21
1 213 113 25
2 201 99 23
3 190 88 29
4 206 104 25
min-max normalization 을 실행한다!
- 모두 0과 1사이의 값이 된것을 알 수 있다.
scaler = preprocessing.MinMaxScaler()
normalized_data = scaler.fit_transform(height_weight_age_df)
normalized_data
array([[0.51851852, 0.32911392, 0.0952381 ],
[0.7037037 , 0.56962025, 0.28571429],
[0.48148148, 0.39240506, 0.19047619],
...,
[0.48148148, 0.37974684, 0.23809524],
[0.38888889, 0.21518987, 0.23809524],
[0.42592593, 0.27848101, 0.52380952]])해당 값을 데이터 프레임에 넣어준다.
- 확인해보면 max의 값은 1 min의 값은 0으로 된 것을 확인할 수 있다.
normalized_df = pd.DataFrame(normalized_data, columns=['Height', 'Weight','Age'])
normalized_df.describe()
Height Weight Age
count 1340.000000 1340.000000 1340.000000
mean 0.482808 0.422586 0.368479
std 0.173481 0.177357 0.161937
min 0.000000 0.000000 0.000000
25% 0.333333 0.316456 0.238095
50% 0.481481 0.392405 0.333333
75% 0.611111 0.569620 0.476190
max 1.000000 1.000000 1.000000- 최종 코드
import pandas as pd
import numpy as np
from sklearn import preprocessing
MBA_FILE_PATH = 'C:/Users/user/Desktop/NBA_player_of_the_week.csv'
nba_player_of_the_week_df = pd.read_csv(MBA_FILE_PATH)
height_weight_age_df = nba_player_of_the_week_df[['Height CM', 'Weight KG', 'Age']]
height_weight_age_df.head()
scaler = preprocessing.MinMaxScaler()
normalized_data = scaler.fit_transform(height_weight_age_df)
normalized_df = pd.DataFrame(normalized_data, columns=['Height', 'Weight','Age'])
728x90
반응형
'Machine learning > Machine learning 강의' 카테고리의 다른 글
| 머신 러닝 데이터 전처리 #2 - One-hot Encoding (0) | 2021.02.09 |
|---|---|
| 머신 러닝 로지스틱 회귀(Logistic Regrssion)#3 - 로지스틱 회귀 구현하기, 와인 종류 예측하기 구현 (0) | 2021.02.09 |
| 머신 러닝 로지스틱 회귀(Logistic Regrssion)#2 - 손실 함수, 로그 손실 (0) | 2021.02.09 |
| 머신 러닝 로지스틱 회귀(Logistic Regrssion)#1 - 로지스틱 회귀란? (0) | 2021.02.08 |
| 머신 러닝 다항 회귀(Polynomial Regression) #2 - sklearn으로 다중 회귀, 당뇨병 예측 학습 프로그램 만들기 (0) | 2021.02.08 |


댓글